
java-lambda和练习之多线程下载工具
多线程
脱离了任务的线程是没有意义的
- 但是不一定要去执行任务
线程是通过Thread类来创建的
任务是通过Runnable接口来实现的
继承Thread类
实现Runnable接口
- 无返回值
实现Callable接口
- 有返回值
Thread
- Thread构造器:无参构造就是不需要指定任务,有参构造可以直接指定线程的任务
1 | public Thread(Runnable target) |
流程
- 创建线程对象,同时指定任务
- 启动线程,start后进入就绪状态,等待获取CPU资源
- 一旦拿到CPU资源,开始执行任务,调用Thread的run方法
1 | public void run(){ |
示例
1 | public class MyThread extends Thread{ |
1 | public class TestApplication { |
缺点
- 继承的缺点在于直接将任务的实现写到了线程当中,耦合度太高,想干其他的,必须要修改源代码
- 解决办法使用类去实现Runnable接口,将任务和线程进行分开
Runnable
线程休眠
1 | public static void main(String[] args) throws InterruptedException { |
- sleep方法到底是让哪一个方法休眠?
- 不在于谁调用sleep,而在与sleep写到哪,如上面的代码,先输出thread1,在输出thread2,休眠的是main方法
- 下面的代码则是先执行thread2,再执行thread1,休眠的是thread1
1 | public static void main(String[] args) { |
lambda表达式
lambda函数式编程,可以将方法的实现作为参数进行传值
使用匿名内部类的形式来减少类的定义
具体可看菜鸟教程
格式
1 | (parameters) -> expression |
1 | Thread thread = new Thread(new Runnable(){ |
1 | //一个类,不过没有名称而已 |
- 进一步使用lambda来进一步简化代码,只把方法的实现进行传值,而不关注其他内容
() -> {}括号实现
1 | Thread thread1 = new Thread(() -> { |
- 普通方法下如果需要调用
MathOperation接口下的operation方法,就需要这样做- 创建一个实现
MathOperation接口的类,调用这个类的new方法创建对象后调用operation方法
- 创建一个实现
1 | public class One { |
- 但是使用lambda表达式就很方便了,代码简化为下方
1 | public class One { |
顺带一提
类型推断
- 有时候你经常看到
List<Dog> dogs2 = new ArrayList<>();这种写法,是不是很好奇为啥不完整的写成List<Dog> dogs2 = new ArrayList<Dog>();,原因很简单,因为左边指明了列表类型为Dog,右边可以推断出来,写不写都无所谓的,这就是类型推断的作用。 - 但是类型推断也不是万能的,不是所有的都可以推断出来的,所以有时候,还是要显示的添加形参类型,例如:先不要管这个代码的具体作用
1 | BinaryOperator b = (x, y)->x*y; |
函数式接口
- 具体可看
- 满足下面规则就是函数式接口
- 只能有一个抽象方法。
- 可以有多个静态方法和默认方法。
- 默认包含Object类的方法。
- 可以很方便我们使用lambda表达式
我们常用的Runnable就是函数式接口
System.out::print
练习项目-下载工具
- 视频地址
- 完成代码地址
- Gitee地址:https://gitee.com/superBiuBiu/Java-Project-Multi-threaded-Downloader
- 待优化点:获取文件名称的时候多次调用了HttpURLConnection类中方法…
ScheduledExecutorService
scheduleAtFixedRate
任务耗费的时间会和设定的period同步开始计时,比如说一个任务耗费6秒,但是设置的是每隔3秒执行,就会导致过了3秒再次执行任务- 倘若在执行任务的时候,耗时超过了间隔时间,则任务执行结束之后直接再次执行,而不是再等待间隔时间执
scheduleWithFixedDelay
- 在执行任务的时候,无论耗时多久,任务执行结束之后都会等待间隔时间之后再继续下次任务。
下载文件进度功能
- 百分比 = 已下载的文件大小 / 要下载的文件大小
- percent = downloadedSize / totalSize;
- 下载速度 = 已下载的文件大小 - 上一次下载的文件大小
- speed = downloadedSize - prevDownloadedSize;
- 剩余时间 = (要下载的文件大小 - 已下载的文件大小) / 下载速度
- remainTime = ( totalSize - downloadedSize ) / speed;
线程池
execute
- 任务提交给线程池
线程满了,队列也慢了,就会执行拒绝策略
创建线程池
1 | public ThreadPoolExecutor(int corePoolSize, |
- 引用下这位博主的图,这里就不绘制了

1 | import java.util.concurrent.ArrayBlockingQueue; |
- 关闭
1 | shutdown():在完成已提交的任务后关闭服务,不再接受新任; |
1 | public static void main(String[] args) { |
- 你也可以使用来等待一会,如果还没有执行完成则强制关闭
1 | public static void main(String[] args) throws InterruptedException { |
切片下载
- 了解下请求头Range等
- 请求某一个资源文件,服务器返回响应如下
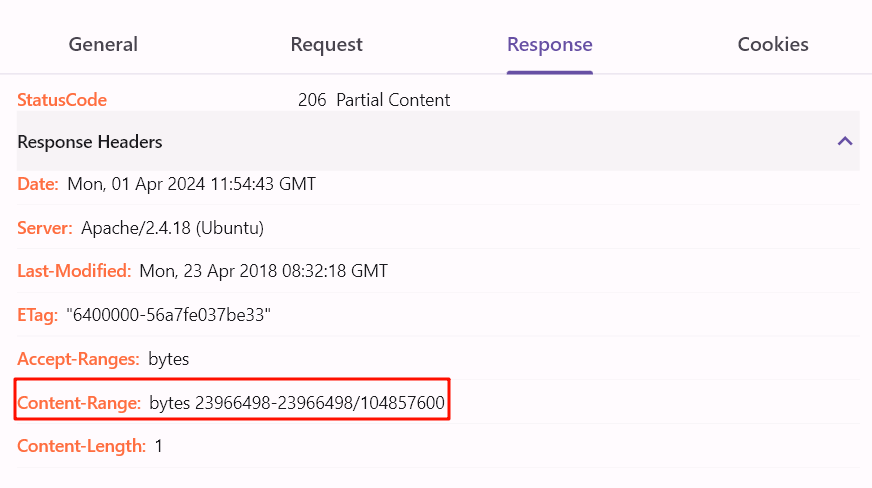
- 这里用到的切片下载就是请求头的
Range- 告知服务端,客户端下载该文件想要从指定的位置开始下载,至于 Range 字段属性值的格式有以下几种:
1 | 语法格式 |
原子类
volatile关键字
Volatile关键字的作用主要有如下两个:
线程的可见性:当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值。
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
顺序一致性:禁止指令重排序。
CountDownLatch
CountDownLatch 是 Java 中的一个并发工具类,用于协调多个线程之间的同步。其作用是让某一个线程等待多个线程的操作完成之后再执行。它可以使一个或多个线程等待一组事件的发生,而其他的线程则可以触发这组事件。
注意不要讲
await写成了wait
问题
- 改为原子类后scheduleAtFixedRate执行不正常(只执行一次)
- 在源码的Java doc中的发现了如下一句话:If any execution of the task encounters anexception, subsequent executions are suppressed.Otherwise, the task will onlyterminate via cancellation or termination of the executor.
- 简单总结就是:如果定时任务执行过程中遇到发生异常,则后面的任务将不再执行。
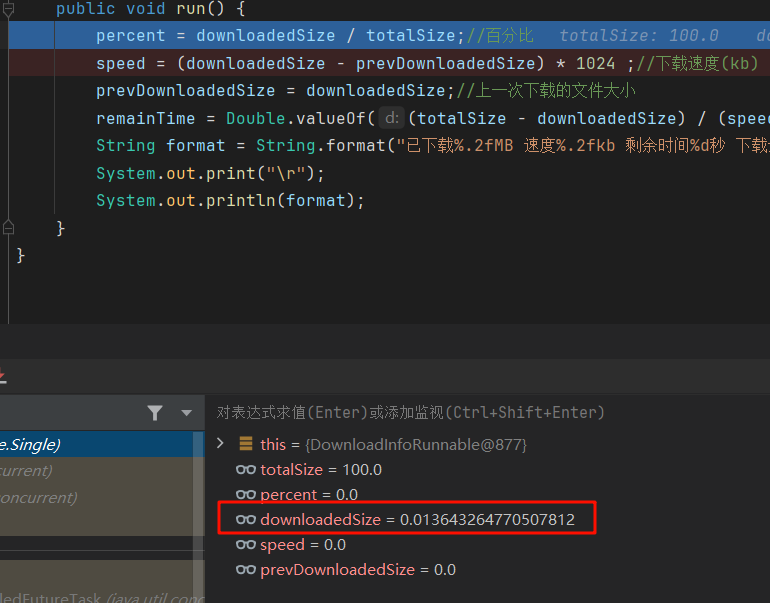
- 之前的
- 可以看到downloadedSize不为空
- 但是现在这个是null
- 解决是延迟1秒调用
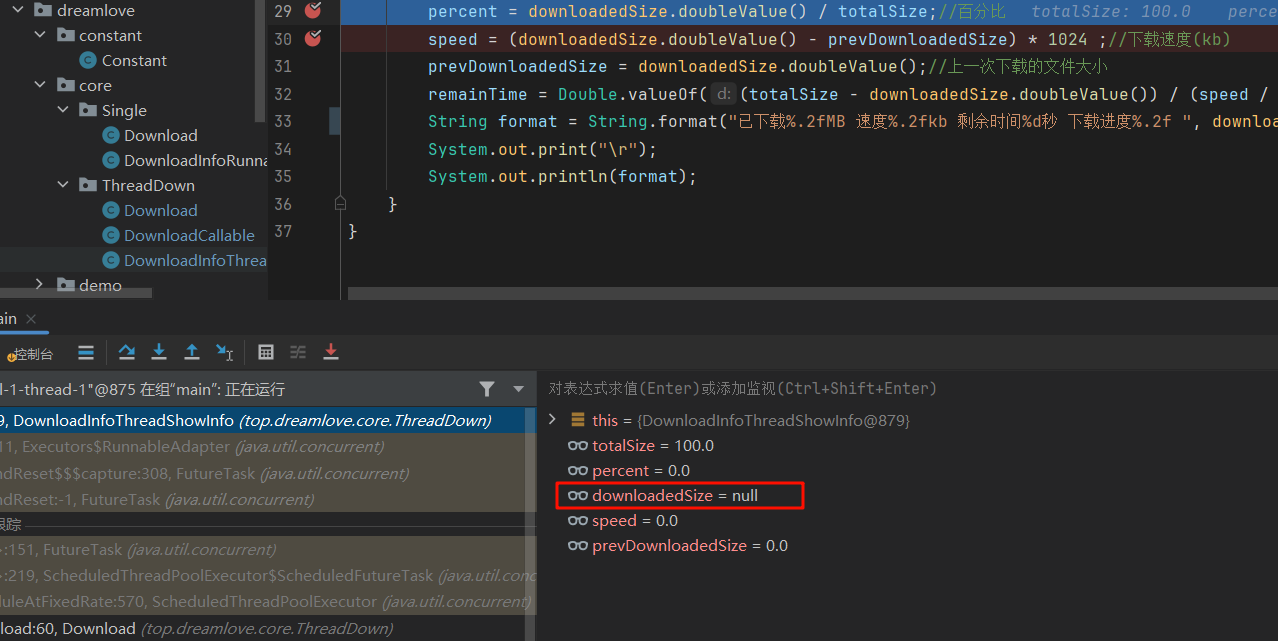
- 可能你改为原子类后依旧是null
- 可能你没有new
- 应该是
public static volatile DoubleAdder downloadedSize = new DoubleAdder();
技巧
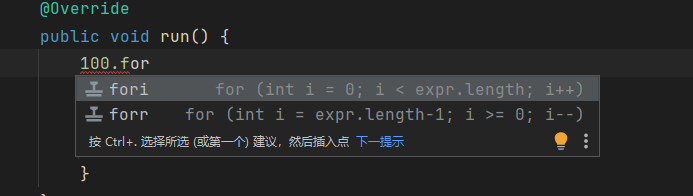
- 快速100次for循环
100.for后tab
输出n次,只保留最新一次的输出结果(java 怎么替换上一次的输出)
\r作用 将光标定义到当前行行首- 在
\r后有新内容时,会先删除之前以前存在过的文本,即只打印\r后面的内容
1
2
3
4
5
6
7
8
9
10
11//将会输出 结果是0结果是1结果是2结果是3结果是4
for (int i = 0; i < 5; i++) {
System.out.print("结果是" + i);
}
//只会输出 结果是4
for (int i = 0; i < 5; i++) {
System.out.print("\r");
System.out.print("结果是" + i);
}- 在
常用的流分类
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象父类 | InputStream | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutStream | FileReader | FileWriter |
| 访问数值 | ByteArrayInputStream | ByteArrayOutStream | CharArrayReader | CharArrayWriter |
| 访问管道 | PipedInputStream | PipedOutStream | PipedReader | PipedWriter |
| 访问字符串 | StringReader | StringWriter | ||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 转换流 | InputStreamReader | OutputStreamWriter | ||
| 对象流 | ObjectInputStream | ObjectOutputStream | ||
| 装饰流 | FilterInputStream | FilterOutputStream | FilterReader | FilterWriter |
| 打印流 | PrintStream | PrintWriter | ||
| 数据过滤流 | DataInputStream | DataOutputStream |
疑问
- lambda写的这么简略,怎么知道是传入的哪一个类?
thread.run和start方法有什么区别?直接调用run有什么问题吗?
- idea的建议对 ‘run()’ 的调用可能应当替换为 ‘start()’
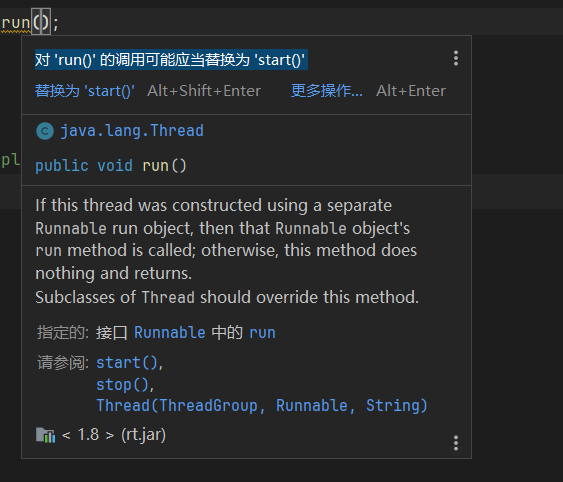
- 直接调用
run就不是多线程了,而是执行里面的一个方法run()方法当作普通方法的方式调用,程序还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码: 而如果直接用run方法,这只是调用一个方法而已,程序中依然只有主线程–这一个线程,其程序执行路径还是只有一条,这样就没有达到写线程的目的。
- 具体可看
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 梦洁小站-属于你我的小天地!

评论
